
SpringCloud面经[下]
Nacos有几种负载均衡策略?
Nacos 作为目前主流的微服务中间件,包含了两个顶级的微服务功能:配置中心和注册中心。
配置中心扫盲
配置中心是一种集中化管理配置的服务,通俗易懂的说就是将本地配置文件“云端化”。 这样做的好处有以下几个:
- 集中管理配置信息:配置中心将不同服务的配置信息集中放在一起进行管理,实现了配置信息的集中存储。
- 动态更新配置:配置中心中的配置信息可以通过操作界面或 API 进行动态更新,无需重启服务就可以应用最新的配置信息。
- 配置信息共享:将配置集中在配置中心中,不同的服务实例可以共享同一套配置信息。
- 配置信息安全:配置中心可以对配置信息提供安全管理、权限控制等管理功能。
- 信息追溯:支持配置版本管理、历史记录等管理功能。
当然,配置中心不可能有负载均衡的功能,所以略过,咱们直接来看注册中心
注册中心扫盲
注册中心(Registry)是分布式系统中的一个组件,用于实现服务的注册与发现。注册中心用于管理服务实例的元数据信息,并提供服务发现和路由的功能。
在微服务架构中,服务之间经常需要互相调用和通信。注册中心的作用是为服务提供一个集中管理和协调的中心,默认情况下,服务将自己的信息注册到注册中心,其他服务可以通过查询注册中心的信息来发现和调用目标服务。
注册中心的核心功能包括以下几个:
- 服务注册:服务提供者在启动时将自己的信息(比如 IP 地址、端口号、服务名称等)注册到注册中心。注册中心维护着一张服务实例的清单。
- 服务发现:服务消费者通过向注册中心查询服务信息,获取可用的服务实例列表。通过注册中心,服务消费者能够找到并连接到目标服务。
- 健康检查:注册中心可以定时检查服务实例的健康状态,并根据服务的状态更新服务实例的可用性。
- 负载均衡:注册中心可以根据负载均衡策略,将请求分发给不同的服务实例,以实现负载均衡和服务高可用。
- 服务路由:在一些高级注册中心中,还可以定义服务路由规则,将请求路由到不同的服务实例,实现更灵活的流量控制和管理。
注册中心与负载均衡
负载均衡严格的来说,并不算是传统注册中心的功能。一般来说服务发现的完整流程应该是先从注 册中心获取到服务的实例列表,然后再根据自身的需求,来选择其中的部分实例或者按照⼀定的流 量分配机制来访问不同的服务提供者,因此注册中心本身⼀般不限定服务消费者的访问策略。
例如 Eureka、Zookeeper 包括 Consul,本身都没有去实现可配置及可扩展的负载均衡机制,Eureka 的 负载均衡是由 Ribbon 来完成的,而 Consul 则是由 Fabio 做负载均衡。
也就是说注册中心和负载均衡,其实完全属于两个不同的东西,注册中心主要提供服务的注册,以及将服务注册的列表交给消费者,至于消费者要使用哪种负载均衡策略?完全可以由自己决定。此时消费者可以通过客户端负载均衡器来实现服务的选择和调用,例如客户端负载均衡器 Ribbon 或 Spring Cloud LoadBalancer。
客户端与服务端负载均衡
客户端负载均衡器通常位于服务的消费者端,主要负责将请求合理地分发给不同的服务提供者。工作原理是客户端在发起请求前,通过负载均衡算法选择一个合适的服务实例进行请求。客户端根据服务实例的健康度、负载状况等指标来决定选择哪个服务实例。常见的客户端负载均衡器有 Ribbon、Feign 等。
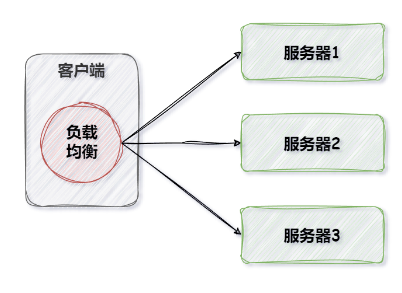
服务端负载均衡器通常被称为反向代理服务器或负载均衡器,它位于服务的提供者端,接收客户端的请求,并根据一定的负载均衡策略将请求分发给后端的多个服务实例。工作原理是将客户端的请求集中到负载均衡器,由负载均衡器将请求分发给多台服务提供者。常见的服务器端负载均衡器有 Nginx、HAProxy 等。
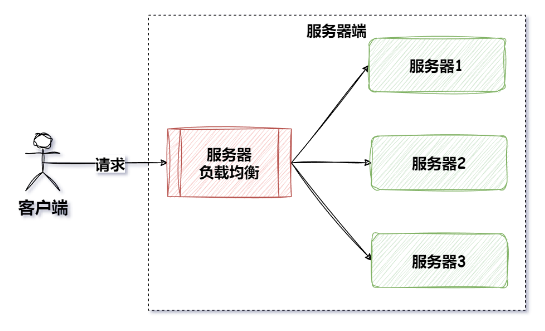
客户端负载均衡 VS 服务端负载均衡
- 客户端负载均衡器的优点是可以实现本地的负载均衡算法,避免了对注册中心的频繁调用,降低了网络开销。它的缺点是每个客户端都需要集成负载均衡器,导致代码冗余和维护复杂性。
- 服务器负载均衡器的优点是可以集中管理请求流量,提供一致的负载均衡策略和配置,对客户端透明。它的缺点是服务器端负载均衡器通常需要独立部署和配置,增加了系统的复杂性和维护成本。并且它很可能成为整个系统的瓶颈(因为客户端需要频繁的调用),所以此时需要考虑其性能和可靠性等问题。
Nacos和负载均衡
然而 Nacos 的注册中心和传统的注册中心不太一样,例如 Eureka、Zookeeper、Consul 等。因为 Nacos 在 0.7.0 之后(包含此版本),它内置了以下两种负载均衡策略:
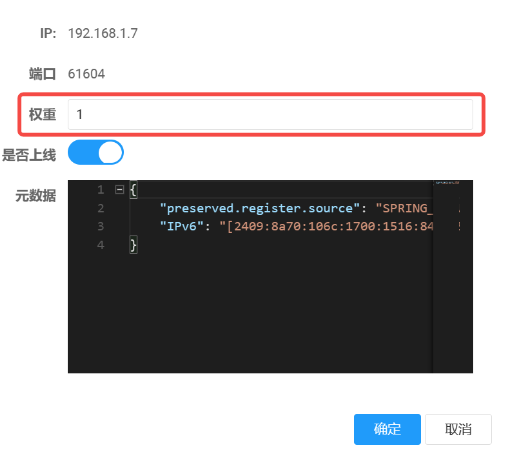
1.基于权重的负载均衡策略,这个在 Nacos 服务编辑的时候也可以看到其设置:
基于第三方 CMDB(地域就近访问)标签的负载均衡策略,这个可以参考官方说明文档:https://nacos.io/zh-cn/blog/cmdb.html
如何实现全链路灰度发布?
灰度发布(Gray Release,也称为灰度发布或金丝雀发布)是指在软件或服务发布过程中,将新版本的功能或服务以较小的比例引入到生产环境中,仅向部分用户或节点提供新功能的一种发布策略。
在传统的全量发布中,新版本的功能会一次性全部部署到所有的用户或节点上。然而,这种方式潜在的风险是,如果新版本存在缺陷或问题,可能会对所有用户或节点产生严重的影响,导致系统崩溃或服务不可用。
相比之下,灰度发布采用较小的规模,并逐步将新版本的功能引入到生产环境中,仅向一小部分用户或节点提供新功能。通过持续监测和评估,可以在发现问题时及时回滚或修复。这种逐步引入新版本的方式可以降低风险,并提高系统的稳定性和可靠性。
实现思路
灰色发布的常见实现思路有以下几种:
- 根据用户划分:根据用户标识或用户组进行划分,在整个用户群体中只选择一小部分用户获得新功能。
- 根据地域划分:在不同地区或不同节点上进行划分,在其中的一小部分地区或节点进行新功能的发布。
- 根据流量划分:根据流量的百分比或请求次数进行划分,只将一部分请求流量引导到新功能上。
而在生产环境中,比较常用的是根据用户标识来实现灰色发布,也就是说先让一小部分用户体验新功能,以发现新服务中可能存在的某种缺陷或不足。
具体实现
Spring Cloud 全链路灰色发布的关键实现思路如下图所示:
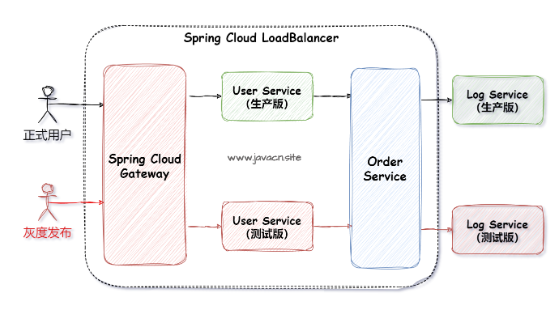
灰度发布的具体实现步骤如下:
- 前端程序在灰度测试的用户 Header 头中打上标签,例如在 Header 中添加
grap-tag: true,其表示要进行灰常测试(访问灰度服务),而其他则为访问正式服务。 - 在负载均衡器 Spring Cloud LoadBalancer 中,拿到 Header 中的“grap-tag”进行判断,如果此标签不为空,并等于“true”的话,表示要访问灰度发布的服务,否则只访问正式的服务。
- 在网关 Spring Cloud Gateway 中,将 Header 标签“grap-tag: true”继续往下一个调用服务中传递。
- 在后续的调用服务中,需要实现以下两个关键功能:
- 在负载均衡器 Spring Cloud LoadBalancer 中,判断灰度发布标签,将请求分发到对应服务。
- 将灰度发布标签(如果存在),继续传递给下一个调用的服务。
经过第四步的反复传递之后,整个 Spring Cloud 全链路的灰度发布就完成了。
核心实现思路和代码
灰度发布的关键实现技术和代码如下。
区分正式服务和灰度服务
在灰度发布的执行流程中,有一个核心的问题,如果在 Spring Cloud LoadBalancer 进行服务调用时,区分正式服务和灰度服务呢?
这个问题的解决方案是:在灰度服务既注册中心的 MetaData(元数据)中标识自己为灰度服务即可,而元数据中没有标识(灰度服务)的则为正式服务,以 Nacos 为例,它的设置如下:
spring:
application:
name: canary-user-service
cloud:
nacos:
discovery:
username: nacos
password: nacos
server-addr: localhost:8848
namespace: public
register-enabled: true
metadata: { "grap-tag":"true" } # 标识自己为灰度服务负载均衡调用灰度服务
Spring Cloud LoadBalancer 判断并调用灰度服务的关键实现代码如下:
private Response<ServiceInstance> getInstanceResponse(List<ServiceInstance> instances,
Request request) {
// 实例为空
if (instances.isEmpty()) {
if (log.isWarnEnabled()) {
log.warn("No servers available for service: " + this.serviceId);
}
return new EmptyResponse();
} else { // 服务不为空
RequestDataContext dataContext = (RequestDataContext) request.getContext();
HttpHeaders headers = dataContext.getClientRequest().getHeaders();
// 判断是否为灰度发布(请求)
if (headers.get(GlobalVariables.GRAY_KEY) != null &&
headers.get(GlobalVariables.GRAY_KEY).get(0).equals("true")) {
// 灰度发布请求,得到新服务实例列表
List<ServiceInstance> findInstances = instances.stream().
filter(s -> s.getMetadata().get(GlobalVariables.GRAY_KEY) != null &&
s.getMetadata().get(GlobalVariables.GRAY_KEY).equals("true"))
.toList();
if (findInstances.size() > 0) { // 存在灰度发布节点
instances = findInstances;
}
} else { // 查询非灰度发布节点
// 灰度发布测试请求,得到新服务实例列表
instances = instances.stream().
filter(s -> s.getMetadata().get(GlobalVariables.GRAY_KEY) == null ||
!s.getMetadata().get(GlobalVariables.GRAY_KEY).equals("true"))
.toList();
}
// 随机正数值 ++i( & 去负数)
int pos = this.position.incrementAndGet() & Integer.MAX_VALUE;
// ++i 数值 % 实例数 取模 -> 轮询算法
int index = pos % instances.size();
// 得到服务实例方法
ServiceInstance instance = (ServiceInstance) instances.get(index);
return new DefaultResponse(instance);
}
}以上代码为自定义负载均衡器,并使用了轮询算法。如果 Header 中有灰度标签,则只查询灰度服务的节点实例,否则则查询出所有的正式节点实例(以供服务调用或服务转发)。
网关传递灰度标识
要在网关 Spring Cloud Gateway 中传递灰度标识,只需要在 Gateway 的全局自定义过滤器中设置 Response 的 Header 即可,具体实现代码如下:
package com.example.gateway.config;
import com.loadbalancer.canary.common.GlobalVariables;
import org.springframework.cloud.gateway.filter.GatewayFilterChain;
import org.springframework.cloud.gateway.filter.GlobalFilter;
import org.springframework.core.Ordered;
import org.springframework.http.HttpStatus;
import org.springframework.http.server.reactive.ServerHttpRequest;
import org.springframework.http.server.reactive.ServerHttpResponse;
import org.springframework.stereotype.Component;
import org.springframework.web.server.ServerWebExchange;
import reactor.core.publisher.Mono;
@Component
public class LoadBalancerFilter implements GlobalFilter {
@Override
public Mono<Void> filter(ServerWebExchange exchange, GatewayFilterChain chain) {
// 得到 request、response 对象
ServerHttpRequest request = exchange.getRequest();
ServerHttpResponse response = exchange.getResponse();
if (request.getQueryParams().getFirst(GlobalVariables.GRAY_KEY) != null) {
// 设置金丝雀标识
response.getHeaders().set(GlobalVariables.GRAY_KEY,
"true");
}
// 此步骤正常,执行下一步
return chain.filter(exchange);
}
}Openfeign 传递灰度标签
HTTP 调用工具 Openfeign 传递灰度标签的实现代码如下:
import feign.RequestInterceptor;
import feign.RequestTemplate;
import jakarta.servlet.http.HttpServletRequest;
import org.springframework.stereotype.Component;
import org.springframework.web.context.request.RequestContextHolder;
import org.springframework.web.context.request.ServletRequestAttributes;
import java.util.Enumeration;
import java.util.LinkedHashMap;
import java.util.Map;
@Component
public class FeignRequestInterceptor implements RequestInterceptor {
@Override
public void apply(RequestTemplate template) {
// 从 RequestContextHolder 中获取 HttpServletRequest
ServletRequestAttributes attributes = (ServletRequestAttributes)
RequestContextHolder.getRequestAttributes();
// 获取 RequestContextHolder 中的信息
Map<String, String> headers = getHeaders(attributes.getRequest());
// 放入 openfeign 的 RequestTemplate 中
for (Map.Entry<String, String> entry : headers.entrySet()) {
template.header(entry.getKey(), entry.getValue());
}
}
/**
* 获取原请求头
*/
private Map<String, String> getHeaders(HttpServletRequest request) {
Map<String, String> map = new LinkedHashMap<>();
Enumeration<String> enumeration = request.getHeaderNames();
if (enumeration != null) {
while (enumeration.hasMoreElements()) {
String key = enumeration.nextElement();
String value = request.getHeader(key);
map.put(key, value);
}
}
return map;
}
}灰度发布是微服务时代保证生产环境安全的必备措施,而其关键实现思路是:
1、注册中心区分正常服务和灰度服务;
2、负载均衡正确转发正常服务和灰度服务;
3、网关和 HTTP 工具传递灰度标签。
这样,我们就完整的实现 Spring Cloud 全链路灰度发布功能了。
说说自适应限流?
限流想必大家都不陌生,它是一种控制资源访问速率的策略,用于保护系统免受过载和崩溃的风险。限流可以控制某个服务、接口或系统在一段时间内能够处理的请求或数据量,以防止系统资源耗尽、性能下降或服务不可用。
常见的限流策略有以下几种:
- 令牌桶算法:基于令牌桶的方式,限制每个单位时间内允许通过的请求量,请求量超出限制的将被拒绝或等待。
- 漏桶算法:基于漏桶的方式,限制系统处理请求的速率,请求速率过快时将被限制或拒绝。
- 计数器算法:通过计数器记录单位时间内的请求次数,并根据设定的阈值进行限制。
通过合理的限流策略,可以保护系统免受恶意攻击、突发流量和资源滥用的影响,确保系统稳定和可靠运行。在实际应用中,限流常用于接口防刷、防止 DDoS 攻击、保护关键服务等场景。
限流实现
在 Java 中,限流的实现方式有很多种,例如以下这些:
- 单机限流:使用 JUC 下的 Semaphore 限流,或一些常用的框架,例如 Google 的 Guava 框架进行限流,但这种限流方式都是基于 JVM 层面的内存级别的单台机器限流。
- 组件限流:单机限流往往不适用于分布式系统,而分布式系统可以通过组件 Sentinel、Hystrix 对整个集群进行限流。
- 反向代理限流(Nginx 限流):通常在网关层的上游,我们会使用 Nginx(反向代理)一起来配合使用,也就是用户请求会先到 Nginx(或 Nginx 集群),然后再将请求转发给网关,网关再调用其他的微服务,从而实现整个流程的请求调用,因此 Nginx 限流也是分布式系统中常用的限流手段。
自适应限流
所谓的自适应限流是结合应用的 Load、CPU 使用率、总体平均 RT、入口 QPS 和并发线程数等几个维度的监控指标,通过自适应的流控策略,让系统的入口流量和系统的负载达到一个平衡,让系统尽可能跑在最大吞吐量的同时保证系统整体的稳定性。
类似的实现思路还有很多,如,自适应自旋锁、还有 K8S 中根据负载进行动态扩容等。
实现思路
以 Sentinel 中的自适应限流来说,它的实现思路是用负载(load1)作为启动控制流量的值,而允许通过的流量由处理请求的能力,即请求的响应时间以及当前系统正在处理的请求速率来决定。
以 Sentinel 中的自适应限流来说,它的实现思路是用负载(load1)作为启动控制流量的值,而允许通过的流量由处理请求的能力,即请求的响应时间以及当前系统正在处理的请求速率来决定。
为什么要这样设计?
长期以来,系统自适应保护的思路是根据硬指标,即系统的负载 (load1) 来做系统过载保护。当系统负载高于某个阈值,就禁止或者减少流量的进入;当 load 开始好转,则恢复流量的进入。这个思路给我们带来了不可避免的两个问题:
load 是一个“果”,如果根据 load 的情况来调节流量的通过率,那么就始终有延迟性。也就意味着通过率的任何调整,都会过一段时间才能看到效果。当前通过率是使 load 恶化的一个动作,那么也至少要过 1 秒之后才能观测到;同理,如果当前通过率调整是让 load 好转的一个动作,也需要 1 秒之后才能继续调整,这样就浪费了系统的处理能力。所以我们看到的曲线,总是会有抖动。
**恢复慢。**想象一下这样的一个场景(真实),出现了这样一个问题,下游应用不可靠,导致应用 RT 很高,从而 load 到了一个很高的点。过了一段时间之后下游应用恢复了,应用 RT 也相应减少。这个时候,其实应该大幅度增大流量的通过率;但是由于这个时候 load 仍然很高,通过率的恢复仍然不高。
TCP BBR 的思想给了我们一个很大的启发。我们应该根据系统能够处理的请求,和允许进来的请求,来做平衡,而不是根据一个间接的指标(系统 load)来做限流。最终我们追求的目标是 在系统不被拖垮的情况下,提高系统的吞吐率,而不是 load 一定要到低于某个阈值。如果我们还是按照固有的思维,超过特定的 load 就禁止流量进入,系统 load 恢复就放开流量,这样做的结果是无论我们怎么调参数,调比例,都是按照果来调节因,都无法取得良好的效果。 所以,Sentinel 在系统自适应限流的做法是,用 load1 作为启动控制流量的值,而允许通过的流量由处理请求的能力,即请求的响应时间以及当前系统正在处理的请求速率来决定。
支持规则
Sentinel 是从单台机器的总体 Load、RT、入口 QPS 和线程数四个维度监控应用数据,让系统尽可能跑在最大吞吐量的同时保证系统整体的稳定性。
系统保护规则是应用整体维度的,而不是资源维度的,并且仅对入口流量生效。入口流量指的是进入应用的流量(EntryType.IN),比如 Web 服务或 Dubbo 服务端接收的请求,都属于入口流量。
注意:系统规则只对入口流量起作用(调用类型为 EntryType.IN),对出口流量无效。可通过 SphU.entry(res, entryType) 指定调用类型,如果不指定,默认是 EntryType.OUT。
Sentinel 支持以下的阈值规则:
- Load(仅对 Linux/Unix-like 机器生效):当系统 load1 超过阈值,且系统当前的并发线程数超过系统容量时才会触发系统保护。系统容量由系统的 maxQps * minRt 计算得出。设定参考值一般是 CPU cores * 2.5。
- CPU usage(1.5.0+ 版本):当系统 CPU 使用率超过阈值即触发系统保护(取值范围 0.0-1.0)。
- RT:当单台机器上所有入口流量的平均 RT 达到阈值即触发系统保护,单位是毫秒。
- 线程数:当单台机器上所有入口流量的并发线程数达到阈值即触发系统保护。
- 入口 QPS:当单台机器上所有入口流量的 QPS 达到阈值即触发系统保护。
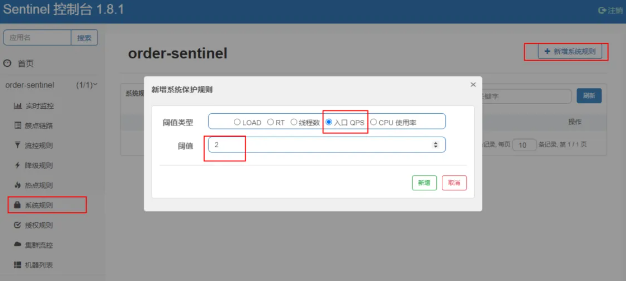
设置自适应限流
在 Sentinel 中,可以通过系统规则 -> 新增系统规则,设置阈值以实现自适应限流功能,如下图所示:
原理分析

我们把系统处理请求的过程想象为一个水管,到来的请求是往这个水管灌水,当系统处理顺畅的时候,请求不需要排队,直接从水管中穿过,这个请求的RT是最短的;反之,当请求堆积的时候,那么处理请求的时间则会变为:排队时间 + 最短处理时间。
推论一:如果我们能够保证水管里的水量,能够让水顺畅的流动,则不会增加排队的请求;也就是说,这个时候的系统负载不会进一步恶化。
我们用 T 来表示(水管内部的水量),用 RT 来表示请求的处理时间,用P来表示进来的请求数,那么一个请求从进入水管道到从水管出来,这个水管会存在 P * RT 个请求。换一句话来说,当 T ≈ QPS * Avg(RT) 的时候,我们可以认为系统的处理能力和允许进入的请求个数达到了平衡,系统的负载不会进一步恶化。
接下来的问题是,水管的水位是可以达到了一个平衡点,但是这个平衡点只能保证水管的水位不再继续增高,但是还面临一个问题,就是在达到平衡点之前,这个水管里已经堆积了多少水。如果之前水管的水已经在一个量级了,那么这个时候系统允许通过的水量可能只能缓慢通过,RT 会大,之前堆积在水管里的水会滞留;反之,如果之前的水管水位偏低,那么又会浪费了系统的处理能力。
推论二:当保持入口的流量使水管出来的流量达到最大值的时候,可以最大利用水管的处理能力。
然而,和 TCP BBR 的不一样的地方在于,还需要用一个系统负载的值(load1)来激发这套机制启动。
注:这种系统自适应算法对于低 load 的请求,它的效果是一个“兜底”的角色。对于不是应用本身造成的 load 高的情况(如其它进程导致的不稳定的情况),效果不明显。
实现代码
以 Sentinel 官方提供的自适应限流代码为例,我们可以再来了解一下它的具体使用:
package com.alibaba.csp.sentinel.demo.system;
import java.util.ArrayList;
import java.util.Collections;
import java.util.List;
import java.util.concurrent.TimeUnit;
import java.util.concurrent.atomic.AtomicInteger;
import com.alibaba.csp.sentinel.util.TimeUtil;
import com.alibaba.csp.sentinel.Entry;
import com.alibaba.csp.sentinel.EntryType;
import com.alibaba.csp.sentinel.SphU;
import com.alibaba.csp.sentinel.slots.block.BlockException;
import com.alibaba.csp.sentinel.slots.system.SystemRule;
import com.alibaba.csp.sentinel.slots.system.SystemRuleManager;
/**
* @author jialiang.linjl
*/
public class SystemGuardDemo {
private static AtomicInteger pass = new AtomicInteger();
private static AtomicInteger block = new AtomicInteger();
private static AtomicInteger total = new AtomicInteger();
private static volatile boolean stop = false;
private static final int threadCount = 100;
private static int seconds = 60 + 40;
public static void main(String[] args) throws Exception {
tick();
initSystemRule();
for (int i = 0; i < threadCount; i++) {
Thread entryThread = new Thread(new Runnable() {
@Override
public void run() {
while (true) {
Entry entry = null;
try {
entry = SphU.entry("methodA", EntryType.IN);
pass.incrementAndGet();
try {
TimeUnit.MILLISECONDS.sleep(20);
} catch (InterruptedException e) {
// ignore
}
} catch (BlockException e1) {
block.incrementAndGet();
try {
TimeUnit.MILLISECONDS.sleep(20);
} catch (InterruptedException e) {
// ignore
}
} catch (Exception e2) {
// biz exception
} finally {
total.incrementAndGet();
if (entry != null) {
entry.exit();
}
}
}
}
});
entryThread.setName("working-thread");
entryThread.start();
}
}
private static void initSystemRule() {
SystemRule rule = new SystemRule();
// max load is 3
rule.setHighestSystemLoad(3.0);
// max cpu usage is 60%
rule.setHighestCpuUsage(0.6);
// max avg rt of all request is 10 ms
rule.setAvgRt(10);
// max total qps is 20
rule.setQps(20);
// max parallel working thread is 10
rule.setMaxThread(10);
SystemRuleManager.loadRules(Collections.singletonList(rule));
}
private static void tick() {
Thread timer = new Thread(new TimerTask());
timer.setName("sentinel-timer-task");
timer.start();
}
static class TimerTask implements Runnable {
@Override
public void run() {
System.out.println("begin to statistic!!!");
long oldTotal = 0;
long oldPass = 0;
long oldBlock = 0;
while (!stop) {
try {
TimeUnit.SECONDS.sleep(1);
} catch (InterruptedException e) {
}
long globalTotal = total.get();
long oneSecondTotal = globalTotal - oldTotal;
oldTotal = globalTotal;
long globalPass = pass.get();
long oneSecondPass = globalPass - oldPass;
oldPass = globalPass;
long globalBlock = block.get();
long oneSecondBlock = globalBlock - oldBlock;
oldBlock = globalBlock;
System.out.println(seconds + ", " + TimeUtil.currentTimeMillis() + ", total:"
+ oneSecondTotal + ", pass:"
+ oneSecondPass + ", block:" + oneSecondBlock);
if (seconds-- <= 0) {
stop = true;
}
}
System.exit(0);
}
}
}